GSoC 2011 – Kate Code Folding – week 2 (Architectural design)
Hello!
Last week I focused on analyzing the interface of the actual implementation. Now, it’s time to develop the new interface.
As I mentioned in my proposal, one of my project’s goals is compatibility: I want to make as few changes as possible in the other sources. This is the reason why I studied the previous implementation for a whole week.
Another goal of my project is 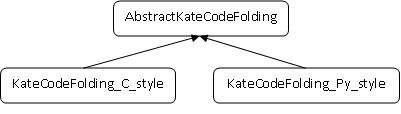 simplicity. The interface will be implemented in an abstract class. This class will be inherited by two other classes: one for C style languages (those who use elements like “{}”) and one for Python style languages (those who use indentation level to define the code blocks), as you can see from the diagram. I believe the code will be simpler and clearer if it is more specialized.
simplicity. The interface will be implemented in an abstract class. This class will be inherited by two other classes: one for C style languages (those who use elements like “{}”) and one for Python style languages (those who use indentation level to define the code blocks), as you can see from the diagram. I believe the code will be simpler and clearer if it is more specialized.
Because this part of the projects it’s about design, I would also like to define my data structures. Of course, there will be a Tree, the code folding tree, and some Nodes. It is very important to know where those Nodes are placed in document (row and column). This info needs to be updated when something changes in your document (e.g.: you add a new line, so all the Nodes change their rows). Because it is very time consuming to search through the folding tree, I suggest adding a second data structure.
For this part, I have a dilemma: whether to use a Vector of Vector
Let’s make it clear: I want to use a Vector of Nodes (actually pointers of Nodes) for each line (because we might have more than one Node per line). But how will be those Vectors stored?
The first option is to use another Vector. The size of this Vector will be the same with the number of rows of the document and Vector[i] = all the nodes placed on the line “i”. This method is easy to be implemented and very fast. The complexity of the updates will be constant and that’s great. So, where is the problem? Memory usage: If we have a 10.000 document lines, then we have about 40 KB of data reserved for this data structure (even though there are no folding nodes at all).
The second option is to use a Set<row,Vector>. For each row, that has at least one folding node, there will be a single entry into this set. This method uses the memory very optimally, but update functions will have a logarithmic (if the set is kept sorted) or linear complexity (much slower than the previous method).
If you have any ideas, feel free to leave some feedback to this article. ;)
Adrian